
tg-me.com/nlp_stuff/291
Last Update:
ارمغانی دیگر از قلمرو مولتیمودال! تولید تصاویر انسانی با استایلهای مختلف.
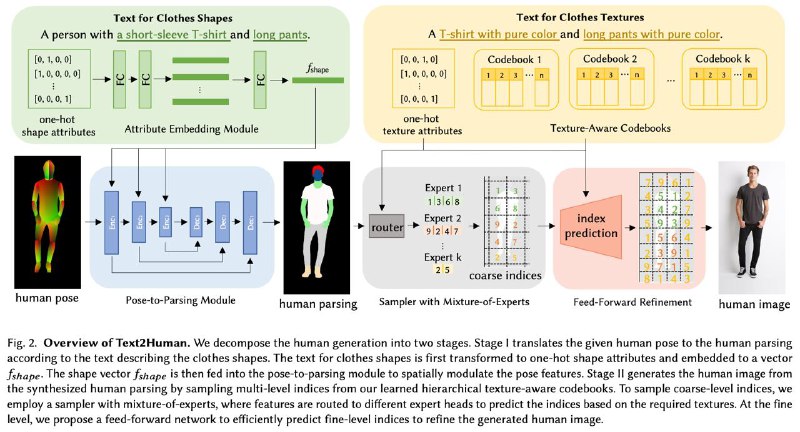
جذابیت مدلهای generative مخصوصا در حوزه تصویر داره میل به بینهایت میکنه. مدلهایی مثل deep fake قبلا خیلی گرد و خاک کردند. اخیرا مدلی بهنام Text2Human معرفی شده که با استفاده از جملات متنی یک استایل از انسان واقعی رو تولید میکنه. روش کارش به این صورته که شما در ورودی وضعیت بدنی (human pose) رو به صورت تصویر میدید (که هر تصویری میتونه باشه و خود دمو هم چندین مثال داره) و فرم لباس و بافت لباس مورد نظرتون رو به صورت جملات متنی میدید و مدل براتون تصاویر آدمهایی با همان ویژگی توصیفشده توسط شما رو تولید میکنه. شیوه کار کلی این مدل در دو گام اصلی خلاصه میشه. در گام اول یک تصویرخام از فرم بدن انسان (human pose)، تبدیل به یک قالب کلی انسان با یک لباس بدون بافت و شکل مشخص میشه (human parsing). سپس در گام دوم خروجی گام اول گرفته میشه و بافت و فرم لباس رو به تصویر گام قبل اضافه میکنه. نمای کلی مدل در تصویر زیر اومده. برای گام اول و تولید بردار بازنمایی قالب بدن انسان از جملات ورودی، از یک شبکه با چندین لایه fully connected استفاده میشه و این بردار بازنمایی به همراه تصویر خام به یک شبکه Auto Encoder داده میشه تا در خروجی یک قالب کلی از بدن انسان که فرم لباس در اون مشخصه ولی رنگ و بافت خاصی نداره رو خروجی بده. سپس برای گام دوم، خروجی تصویر گام اول به دو شبکه Auto Encoder همکار داده میشه که یکی مسوول بررسی ویژگیهای سطح بالای تصویر استایل انسان هست و دیگری به صورت ریزدانهتری فیچرها رو در نظر میگیره (فرض کنید در شبکه اول هر چند ده پیکسل مجاور هم تجمیع میشوند و به شبکه داده میشوند در حالیکه در شبکه دوم هر پیکسل یک درایه از بردار ورودی را تشکیل میدهد). از طرفی بازنمایی جملات نیز به این شبکهها داده میشود. سپس برای اینکه این دو شبکه همکاری داشته باشند خروجی دیکودر شبکه اول به ورودی دیکودر شبکه دوم داده میشه. یعنی شبکه دوم علاوه بر دریافت خروجی encoder خودش، خروجی دیکودر شبکه اول رو هم دریافت میکنه و بعد اقدام به بازسازی تصویر نهایی میکنه. معماری این قسمت رو هم در تصاویر میتونید ببینید. این مدل بر روی هاگینگفیس هم serve شده و میتونید دموش رو به صورت رایگان مشاهده کنید.
لینک مقاله:
https://arxiv.org/abs/2205.15996
لینک دمو:
https://huggingface.co/spaces/CVPR/Text2Human
لینک گیتهاب:
https://github.com/yumingj/Text2Human
#read
#paper
@nlp_stuff
BY NLP stuff
Share with your friend now:
tg-me.com/nlp_stuff/291